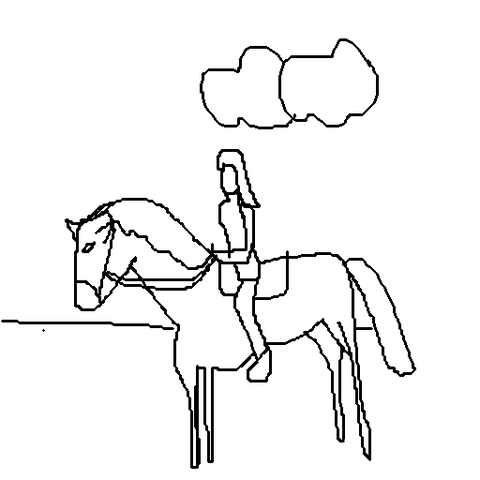
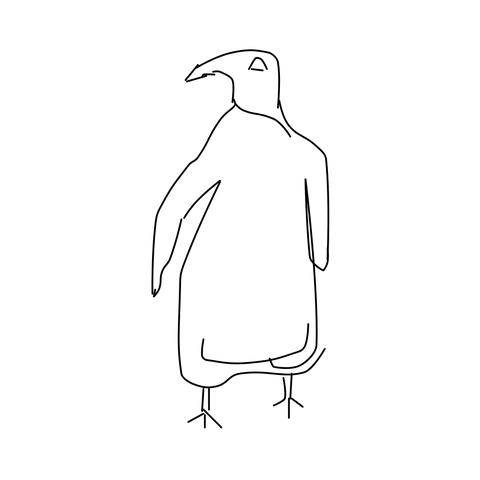
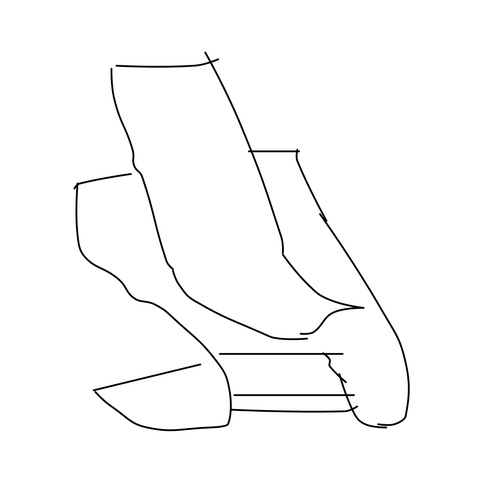
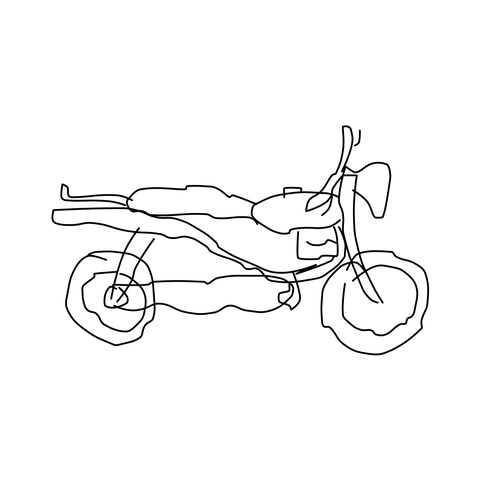
Sketch → Multi-View
Given a single freehand sketch and a text caption, our method generates geometrically consistent multi-view images spanning a full 360° azimuth orbit at 4 different elevations, all in a single forward pass.
ECCV 2026
TLDR: From a single freehand sketch, we generate 33 geometrically consistent multi-view images in one forward pass (~50 s). No reference photograph needed.
We tackle a new problem: generating geometrically consistent multi-view scenes from a single freehand sketch. Freehand sketches are the most geometrically impoverished input one could offer a multi-view generator. They convey scene intent through abstract strokes while introducing spatial distortions that actively conflict with any consistent 3D interpretation. No prior method attempts this; existing multi-view approaches require photographs or text, while sketch-to-3D methods need multiple views or costly per-scene optimisation.
We address three compounding challenges: (1) absent training data, (2) the need for geometric reasoning from distorted 2D input, and (3) cross-view consistency, through three mutually reinforcing contributions: (i) a curated dataset of ~9k sketch–multiview samples, constructed via an automated generation and filtering pipeline; (ii) Parallel Camera-Aware Attention Adapters (CA3) that inject geometric inductive biases into the video transformer; and (iii) a Sparse Correspondence Supervision Loss (CSL) derived from Structure-from-Motion reconstructions.
Our framework synthesizes all views in a single denoising process without requiring reference images, iterative refinement, or per-scene optimization. Our approach outperforms state-of-the-art two-stage baselines, improving realism (FID) by over 60% and geometric consistency (Corr-Acc) by 23%, while providing up to 3.7× inference speedup.
Our single-stage framework encodes a freehand sketch, denoises it through a video DiT augmented with lightweight Camera-Aware Attention Adapters (CA3), and generates N = 33 multi-view frames in one forward pass. During training, Structure-from-Motion correspondences supervise the adapter's latent projections via a sparse Correspondence Supervision Loss (CSL).
9,222 curated sketch–multiview samples (33 views each), constructed via automated generation, segmentation-based filtering, and multi-view generation from FS-COCO freehand sketches.
Lightweight parallel camera attention adapters that inject Projective Rotary Position Encoding (PRoPE) into a pretrained video DiT, adding only 2.7% additional parameters.
Sparse InfoNCE loss on adapter query–key projections using SfM correspondences, directly teaching the model cross-view geometric consistency.

No existing dataset pairs freehand scene sketches with geometrically consistent multi-view images. We construct the S2MV dataset through an automated pipeline: multi-seed generation from sketch+text, semantic segmentation-based filtering (mIoU), and multi-view generation at 33 target camera poses.

We compare against two state-of-the-art novel-view synthesis methods adapted via a shared two-stage pipeline (FLUX → NVS). Our single-stage method produces more realistic and geometrically consistent views.
| Method | Stages | Time | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FID ↓ | CLIP-I ↑ | Corr-Acc ↑ |
|---|---|---|---|---|---|---|---|---|
| SEVA | 2 | ~3.1 min | 11.310 | 0.265 | 0.705 | 46.34 | 0.756 | 0.161 |
| ViewCrafter | 2 | ~35 min | 11.148 | 0.338 | 0.737 | 48.22 | 0.773 | 0.136 |
| Ours | 1 | ~50 s | 12.169 | 0.302 | 0.632 | 18.49 | 0.828 | 0.199 |
Select an example to compare methods side-by-side. 8 azimuth views at 45° intervals, elevation 0°.
All components are mutually reinforcing — removing any one degrades both per-view quality and geometric consistency.
| Configuration | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FID ↓ | CLIP-I ↑ | Corr-Acc ↑ | |
|---|---|---|---|---|---|---|---|
| (a) | Full model (CA3 + CSL + LoRA) | 12.169 | 0.302 | 0.632 | 18.49 | 0.828 | 0.199 |
| (b) | w/o CSL | 12.073 | 0.287 | 0.664 | 20.37 | 0.817 | 0.175 |
| (c) | w/o CA3 (LoRA only) | 5.026 | 0.266 | 0.819 | 266.06 | 0.632 | 0.183 |
| (d) | w/o LoRA (CA3 only) | 12.211 | 0.304 | 0.644 | 19.27 | 0.823 | 0.188 |
| (e) | w/o frame replication | 12.198 | 0.304 | 0.652 | 42.54 | 0.786 | 0.174 |
Query pixel (red dot) in the front view; heatmaps show CA3 attention at layer 20 over three target viewpoints. With CSL, attention concentrates on geometrically correct regions. Without CSL, it is diffuse and spatially unstructured.
 Query
Query 180°, 0°
180°, 0° 315°, 0°
315°, 0° 135°, −30°
135°, −30° Query
Query 180°, 0°
180°, 0° 315°, 0°
315°, 0° 135°, −30°
135°, −30° Query
Query 180°, 0°
180°, 0° 315°, 0°
315°, 0° 135°, −30°
135°, −30° Query
Query 180°, 0°
180°, 0° 315°, 0°
315°, 0° 135°, −30°
135°, −30°Trained exclusively on FS-COCO sketches, our model generalises zero-shot to unseen domains: TU-Berlin (single-object) and InkScenes (dense scene compositions).
Browse 50 test samples side-by-side across all methods vs. ground truth. Filter by elevation, toggle methods, and zoom into individual views.
Open Full Gallery
@article{bourouis2026geometrically,
title={Geometrically Consistent Multi-View Scene Generation from Freehand Sketches},
author={Bourouis, Ahmed and Ozkan, Savas and Maracani, Andrea and Song, Yi-Zhe and Ozay, Mete},
journal={arXiv preprint arXiv:2604.14302},
year={2026}
}