Method
Our framework consists of two levels: I. Holistic Scene Sketch Understanding and II. Targeting individual categories disentanglement. Please refer to Sec. 3 in the paper for details.
We study the underexplored but fundamental vision problem of machine understanding of abstract freehand scene sketches
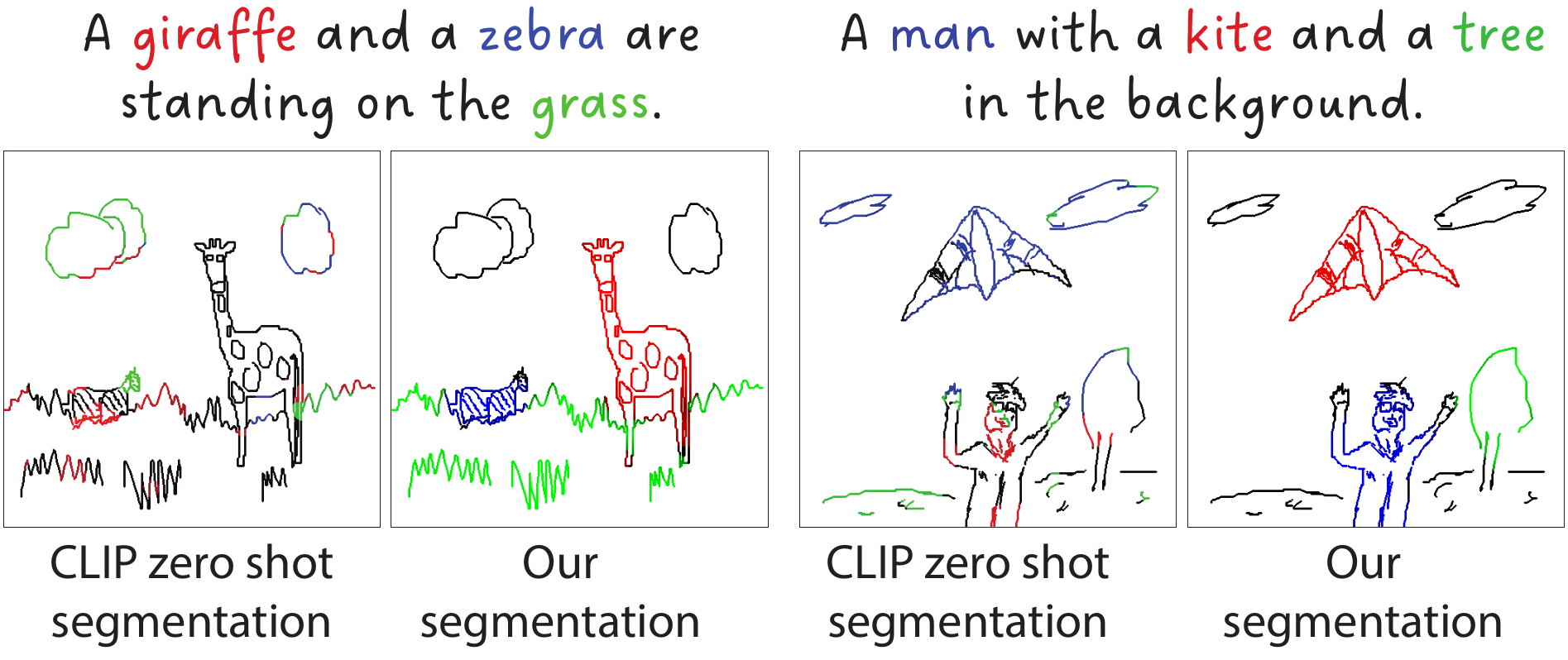
We introduce a sketch encoder that results in semantically- aware feature space, which we evaluate by testing its performance on a semantic sketch seg- mentation task. To train our model we rely only on the availability of bitmap sketches with their brief captions and do not require any pixel-level annotations. To obtain generalization to a large set of sketches and categories, we build on a vision transformer encoder pretrained with the CLIP model. We freeze the text encoder and perform visual-prompt tuning of the visual encoder branch while introducing a set of critical modifications. Firstly, we augment the classical key-query (k-q) self-attention blocks with value-value (v-v) self-attention blocks. Central to our model is a two-level hierarchical network design that enables efficient semantic disentanglement: The first level ensures holistic scene sketch encoding, and the second level focuses on individual categories. We, then, in the second level of the hierarchy, introduce a cross-attention between textual and visual branches.
Our method outperforms zero-shot CLIP pixel accuracy of segmentation results by 37 points, reaching an accuracy of 85.5% on the FS-COCO sketch dataset. Finally, we conduct a user study that allows us to identify further improvements needed over our method to reconcile machine and human understanding of scene sketches.
Our framework consists of two levels: I. Holistic Scene Sketch Understanding and II. Targeting individual categories disentanglement. Please refer to Sec. 3 in the paper for details.
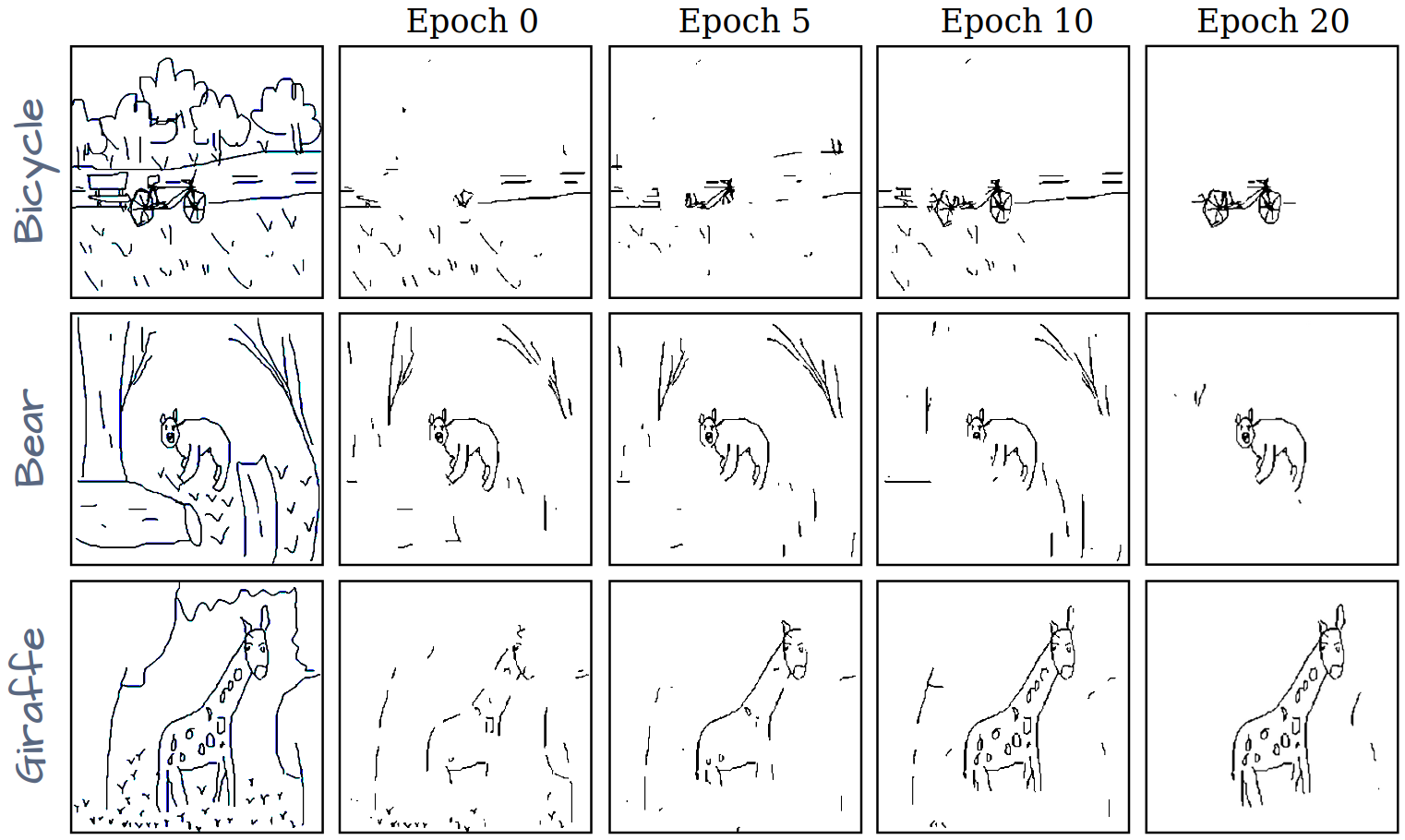
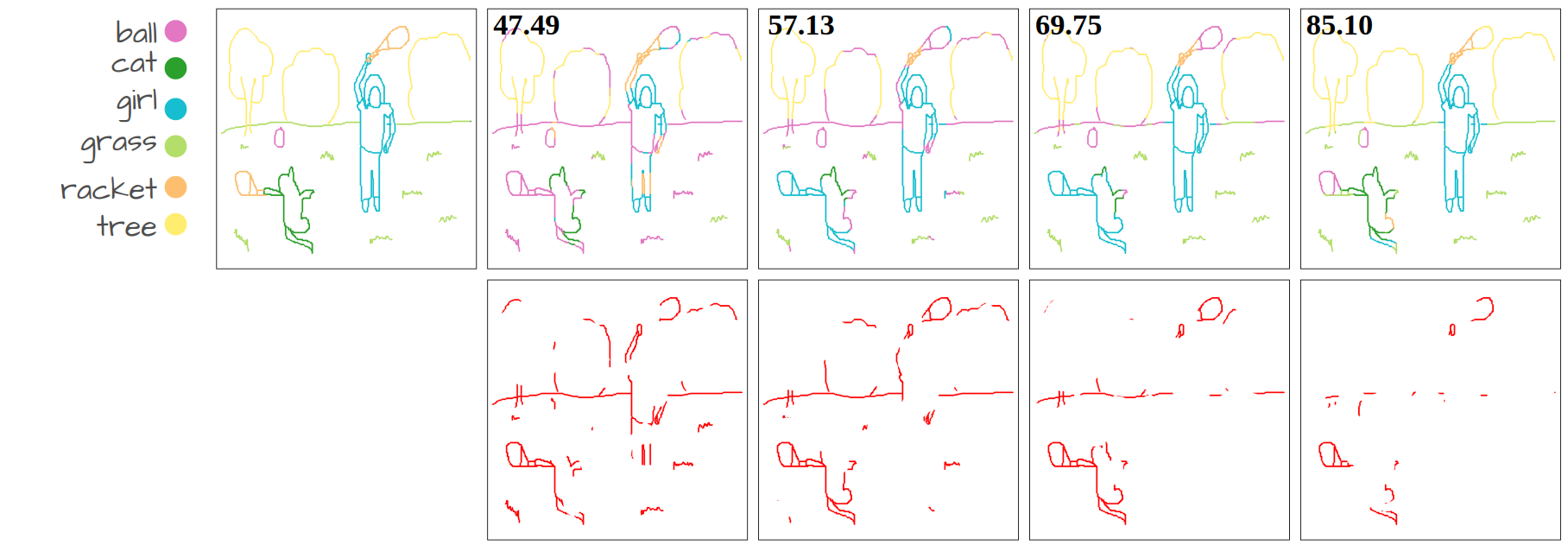
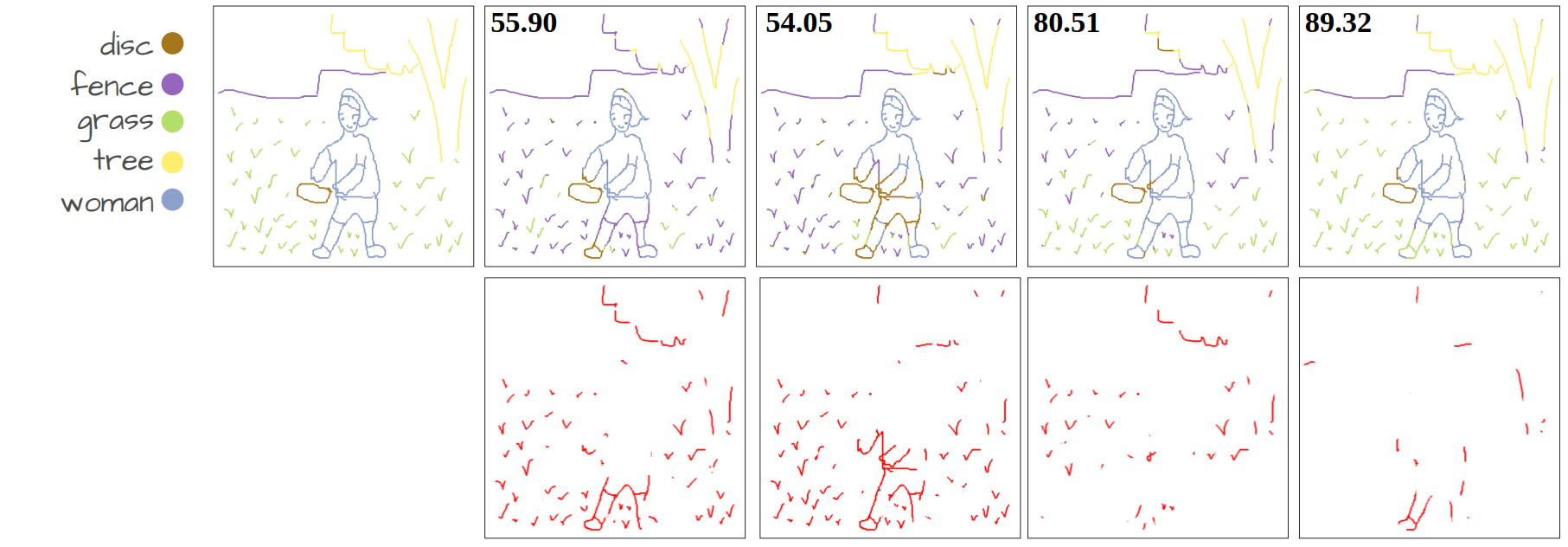
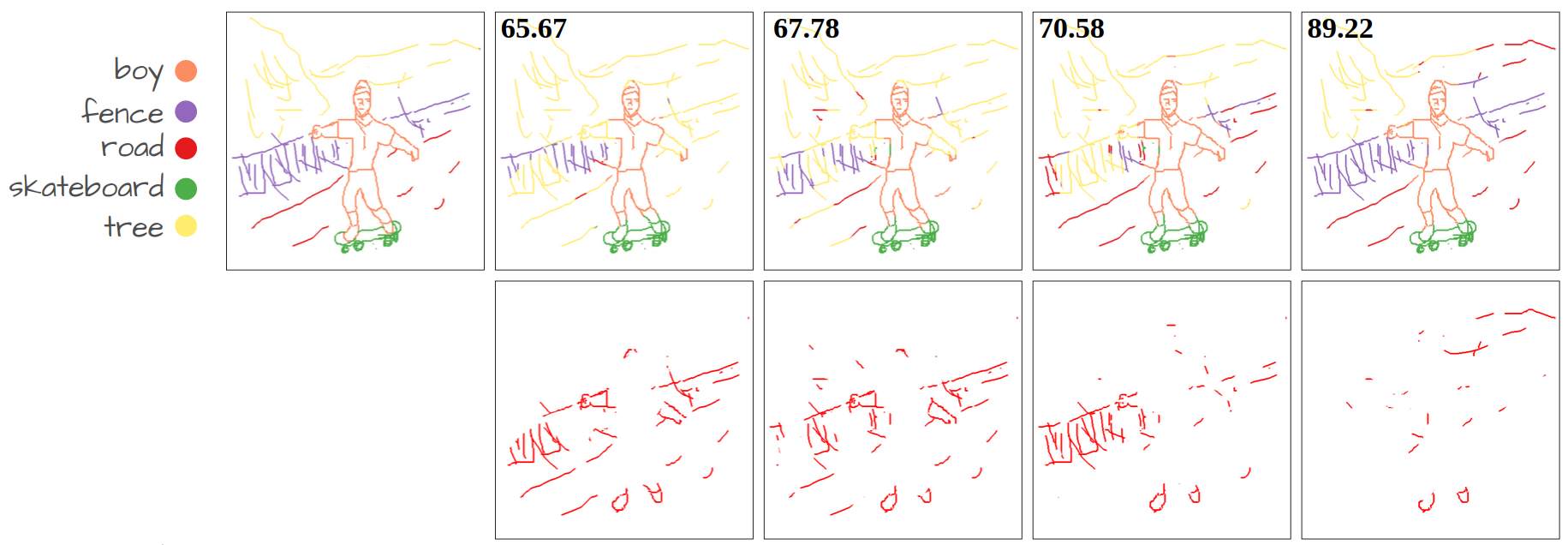
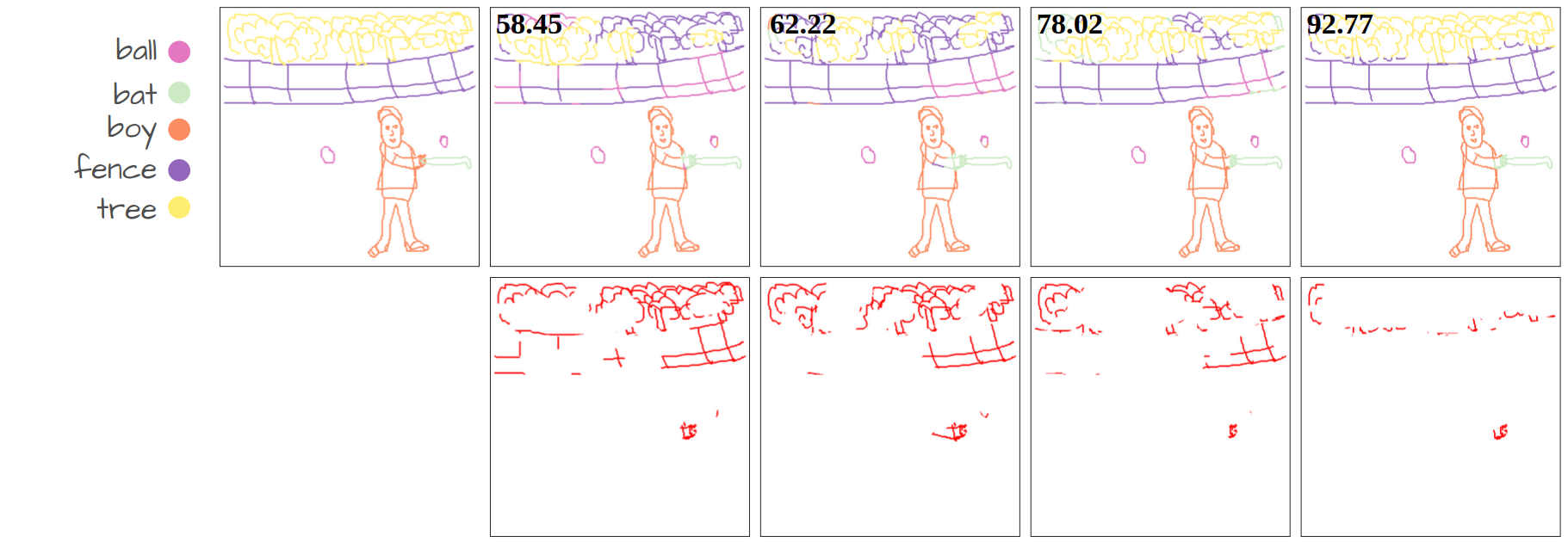
Visualization of disentanglement over epochs. Only pixels with similarity scores above a certain threshold are retained. We make the threshold learnable, eliminating the need for manual tuning. More importantly, the threshold value increases over epochs as the model becomes more confident in its predictions, allowing the model to obtain strong disentanglement performance.
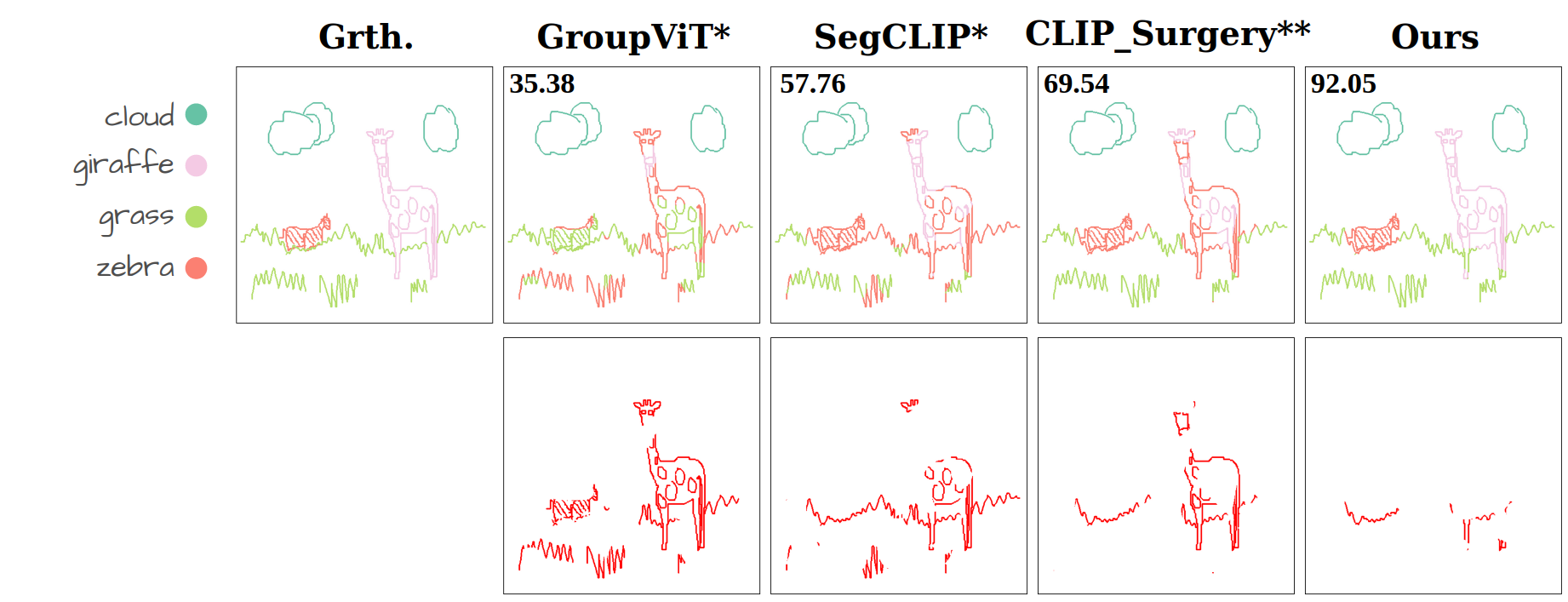
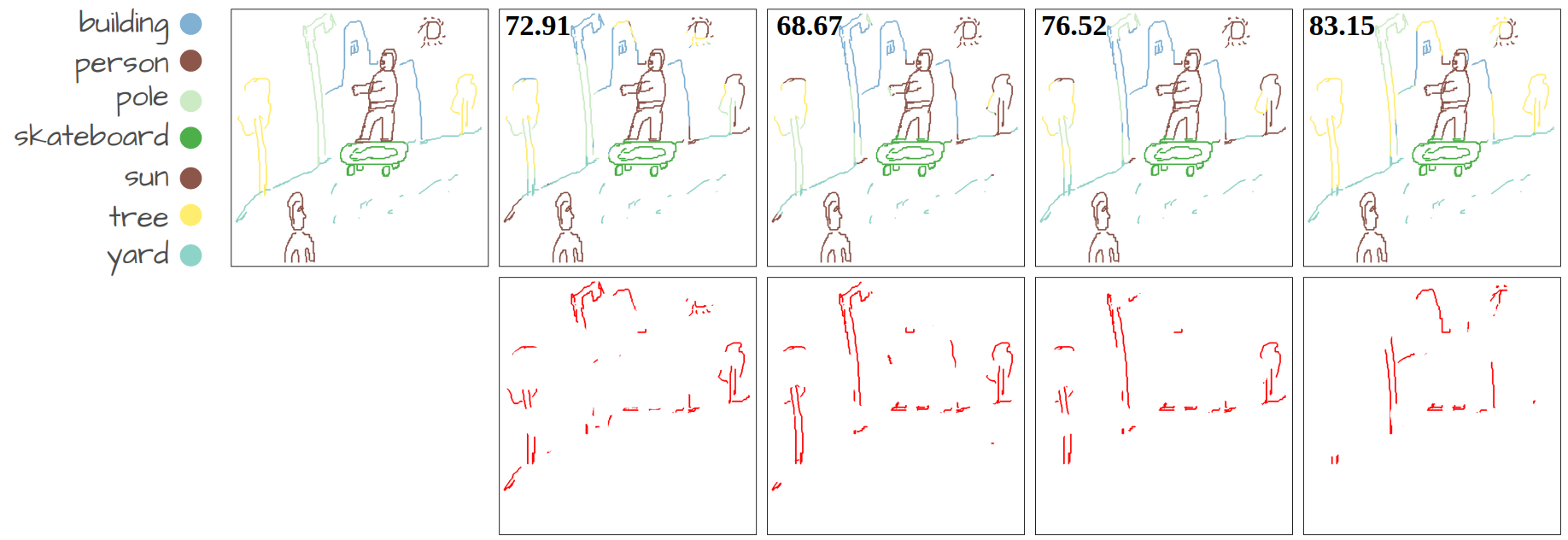
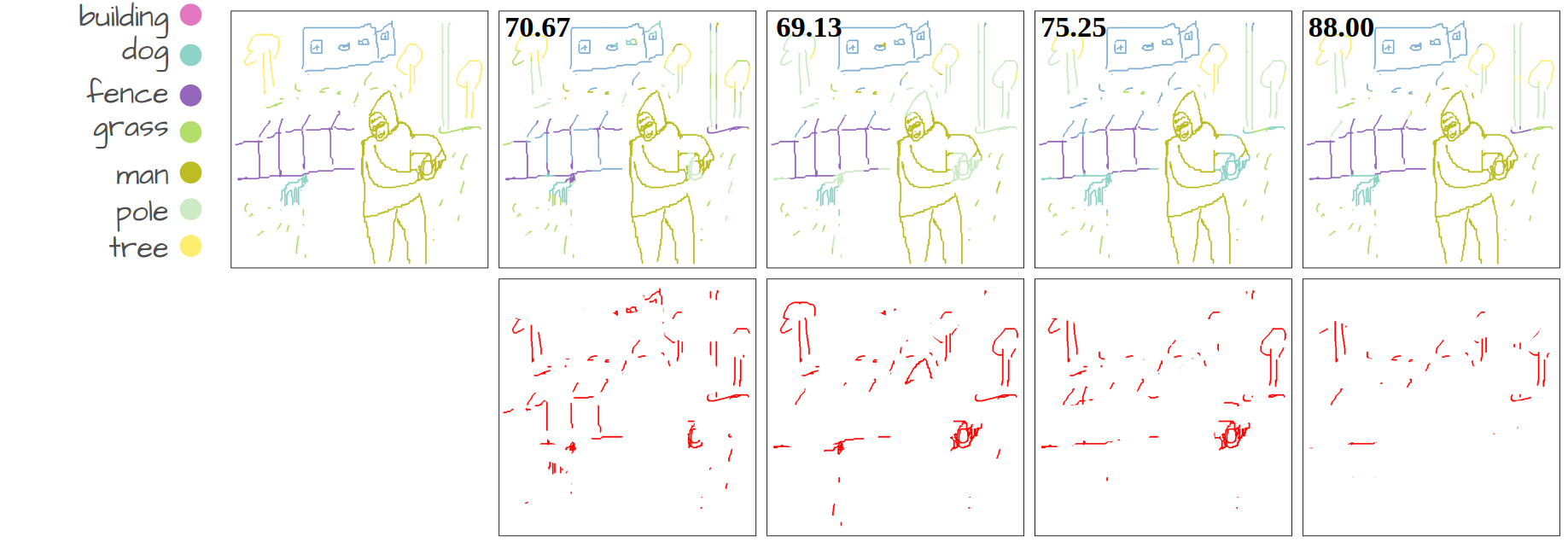
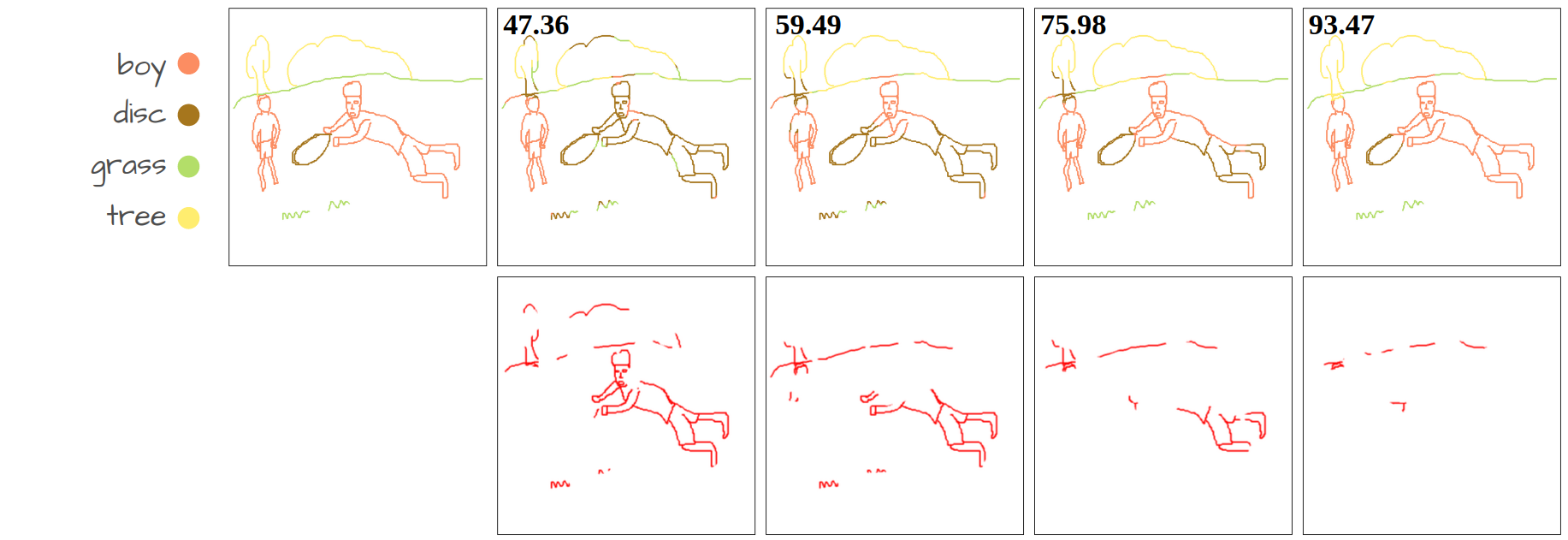
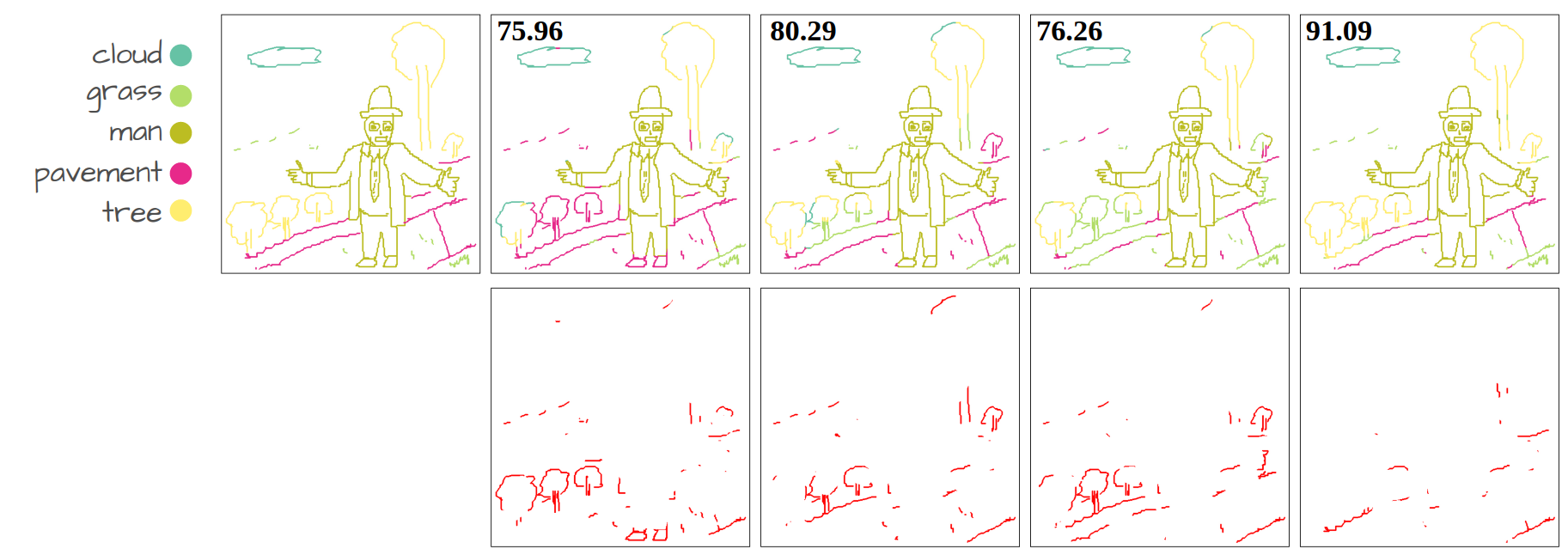
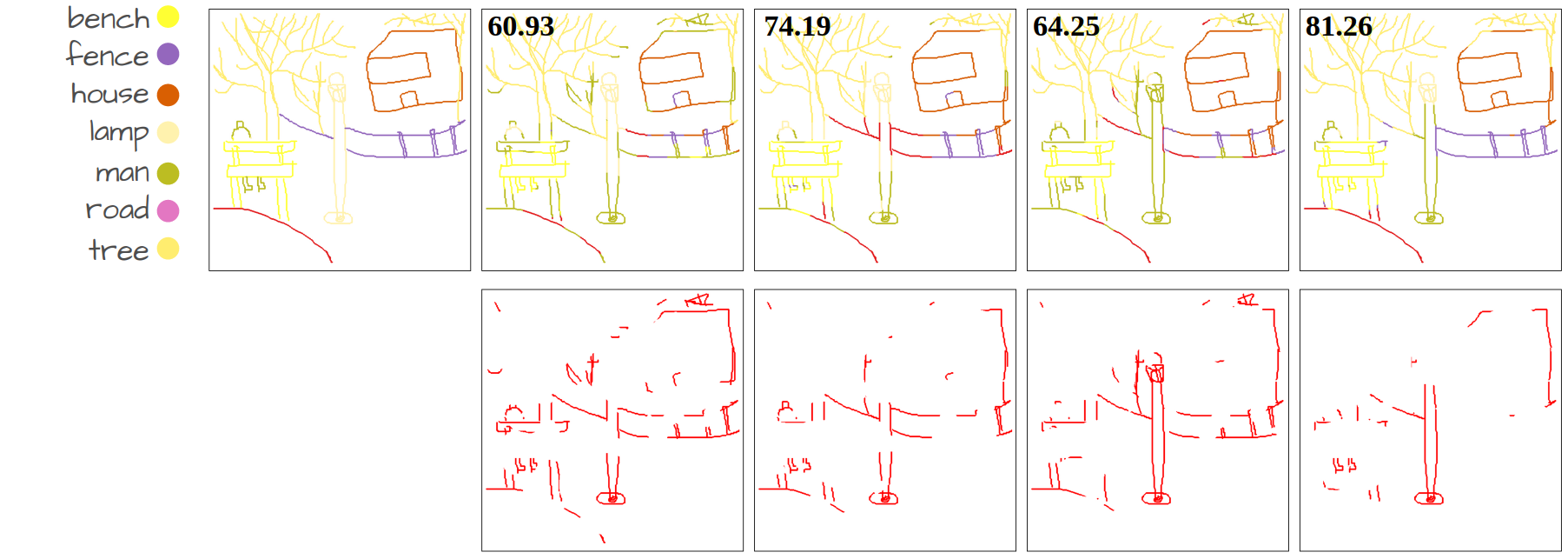
Our method compared to language-supervised baselines fine-tuned on the same dataset. The numbers show Acc@P (pixel accuracy) values. The error maps in red represent the mis-segmented pixels.
@inproceedings{bourouis2024open,
title={Open Vocabulary Semantic Scene Sketch Understanding},
author={Bourouis, Ahmed and Fan, Judith E and Gryaditskaya, Yulia},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4176--4186},
year={2024}
}